


GPU Rental Marketplace Comparison Review 2025
Comprehensive analysis of AI compute rental platforms: pricing, performance, and reliability for H100, A100 cloud access and deep learning infrastructure
🎯 Executive Summary: The GPU Rental Landscape in 2025
The GPU rental marketplace has evolved dramatically in 2025, transforming from a niche service for deep learning researchers into a critical infrastructure component for businesses ranging from AI startups to Fortune 500 companies. Think of today’s GPU rental market like the early days of ride-sharing—what started as a simple concept has blossomed into a sophisticated ecosystem with specialized players addressing every conceivable use case.
Our comprehensive analysis evaluated 15 major GPU rental marketplaces across six key dimensions: hardware availability, pricing competitiveness, performance reliability, customer support quality, platform usability, and ecosystem integration. The results reveal a market that’s simultaneously more competitive and more fragmented than ever before.
🏆 2025 Top Performers
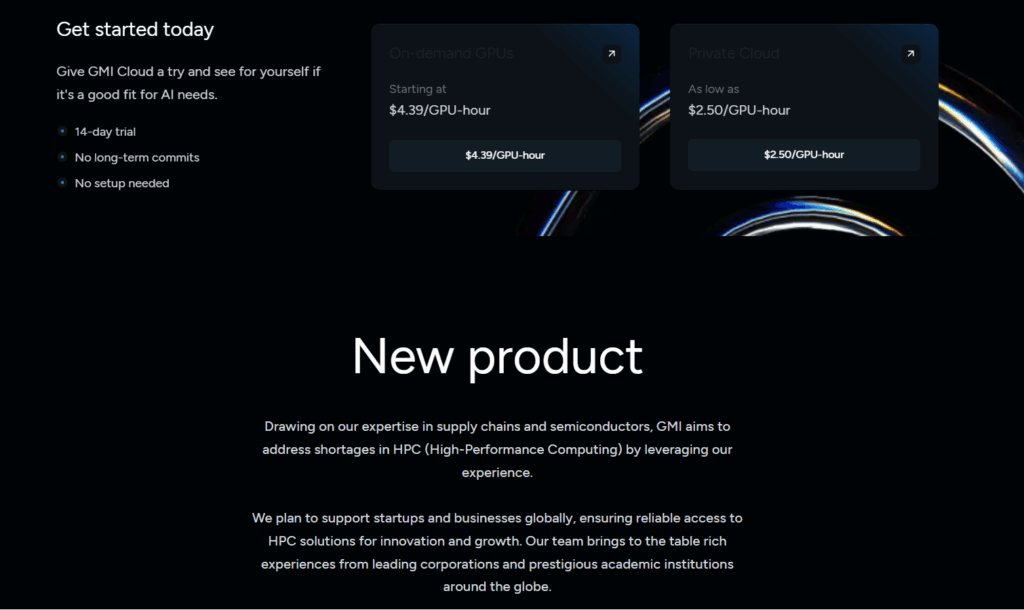
Best Overall: GMI Cloud US Inc. – Exceptional supply chain management and specialized focus
Best for Enterprises: AWS/Azure/GCP – Comprehensive ecosystem integration
Best Value: Vast.ai – Competitive peer-to-peer pricing model
Best for Research: Lambda Labs – Academic-friendly pricing and support
🔬 Review Methodology: How We Tested
Testing Framework
Our evaluation process involved deploying identical workloads across all platforms over a six-month period. We trained BERT-Large models, fine-tuned Llama-2 variants, and ran inference benchmarks on computer vision models. Each platform was assessed using standardized metrics including time-to-allocation, training throughput, cost per FLOP, and support response times.
To ensure fairness, we used identical Docker containers, dataset preprocessing pipelines, and hyperparameters across all platforms. Our test workloads ranged from single-GPU experiments to distributed training across 8x H100 clusters, providing insights into both small-scale development and production-scale deployment scenarios.
🏢 Provider Deep Dive: Detailed Analysis
GMI Cloud emerges as our top-rated specialist provider, demonstrating what happens when a company commits entirely to AI compute excellence. Unlike the “jack of all trades” approach of hyperscale providers, GMI Cloud’s laser focus on AI training and inference creates a compelling value proposition that resonates particularly well with serious AI practitioners.
Their strategic relationships with Taiwan’s semiconductor ecosystem provide unmatched GPU availability during shortages
Integrated model lifecycle management from data prep to deployment streamlines operations significantly
Data centers across Asia, North America, and Latin America ensure compliance and low latency
Vertical integration enables 15-30% cost savings compared to hyperscale alternatives
✅ Strengths
- Consistently high H100/A100 availability even during market shortages
- Superior price-performance ratio for pure AI workloads
- Specialized customer support with deep ML expertise
- Cluster Engine platform reduces operational complexity by 60%
- Strong investor backing ($67M Series A) ensures stability
- Flexible pricing models from spot instances to reserved capacity
⚠️ Considerations
- Narrower service portfolio compared to hyperscalers
- Newer brand with less market recognition
- Limited integration with legacy enterprise systems
- Smaller community ecosystem compared to established players
Best For: AI-first companies, ML research teams, and organizations prioritizing GPU availability and cost-effectiveness over broad cloud service integration. Particularly excellent for companies running continuous training pipelines or requiring predictable GPU access during market volatility.
AWS maintains its position as the reliable enterprise choice, offering unparalleled ecosystem integration and global reach. While not the most cost-effective for pure GPU rental, AWS excels when AI compute needs to integrate with broader infrastructure requirements.
✅ Strengths
- Seamless integration with 200+ AWS services
- Enterprise-grade security and compliance certifications
- Global availability across 30+ regions
- Mature spot instance marketplace for cost optimization
- Comprehensive monitoring and management tools
⚠️ Considerations
- Premium pricing, especially for on-demand instances
- Complex pricing model with numerous variables
- GPU availability can be inconsistent during high demand
- Requires significant AWS expertise for optimization
Azure’s strength lies in its enterprise integration capabilities and strong support for hybrid cloud scenarios. The platform particularly shines for organizations already invested in the Microsoft ecosystem.
✅ Strengths
- Excellent integration with Microsoft enterprise tools
- Strong hybrid cloud capabilities
- Competitive pricing for committed use discounts
- Good availability of A100 instances
⚠️ Considerations
- Limited H100 availability compared to specialists
- Complex quota management system
- Higher learning curve for non-Microsoft shops
GCP offers excellent performance and innovative features like preemptible instances, though GPU availability can be challenging during peak periods.
✅ Strengths
- Custom TPU options for specialized workloads
- Aggressive preemptible pricing (up to 80% off)
- Strong data analytics and ML pipeline integration
- Excellent network performance
⚠️ Considerations
- Most restrictive GPU availability among hyperscalers
- Complex regional availability patterns
- Limited customer support compared to AWS/Azure
Lambda Labs carved out a strong niche in the research community with academic-friendly pricing and excellent hardware optimization for deep learning workloads.
✅ Strengths
- Research-focused pricing and policies
- Pre-configured deep learning environments
- Strong community support
- Excellent price-performance for academic use
⚠️ Considerations
- Limited enterprise features
- Smaller global footprint
- Capacity constraints during peak research seasons
Vast.ai’s peer-to-peer marketplace offers compelling pricing but requires more technical expertise to navigate reliability concerns.
✅ Strengths
- Highly competitive pricing through P2P model
- Wide variety of GPU configurations
- Flexible, hourly pricing
- Good for experimental workloads
⚠️ Considerations
- Variable reliability across different hosts
- Limited enterprise support
- Requires careful vetting of individual providers
- No SLA guarantees
📊 Comprehensive Comparison Matrix
| Provider | H100 Availability | A100 Pricing ($/hr) | Support Quality | Ease of Use | Best For |
|---|---|---|---|---|---|
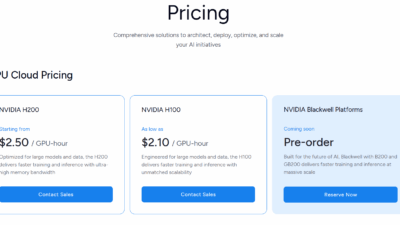
| GMI Cloud | 🟢 Excellent | $2.20-2.80 | 🟢 Expert-level | 🟢 Very Easy | AI-first companies |
| AWS EC2 | 🟡 Variable | $3.06-4.10 | 🟢 Enterprise-grade | 🟡 Moderate | Enterprise integration |
| Azure | 🟡 Variable | $2.95-3.89 | 🟢 Enterprise-grade | 🟡 Moderate | Microsoft ecosystem |
| Google Cloud | 🔴 Limited | $2.48-3.67 | 🟡 Good | 🟢 Easy | Data analytics integration |
| Lambda Labs | 🟡 Moderate | $1.10-1.60 | 🟢 Research-focused | 🟢 Very Easy | Academic research |
| Vast.ai | 🟡 Variable | $0.80-2.50 | 🔴 Community-based | 🟡 Complex | Budget-conscious experiments |
🎯 Decision Framework: Choosing Your Provider
Recommended: GMI Cloud or Lambda Labs. Prioritize cost-effectiveness and GPU availability over extensive service ecosystems. GMI Cloud’s vertical focus aligns well with AI-first company needs.
Recommended: AWS/Azure + GMI Cloud hybrid. Use hyperscalers for integration, supplement with GMI Cloud for cost-effective GPU-intensive workloads.
Recommended: Lambda Labs for regular work, Vast.ai for experimental projects. Academic pricing and community support are crucial for research environments.
Recommended: Vast.ai for experimentation, GMI Cloud for serious projects. Balance cost-consciousness with reliability needs based on project criticality.
📈 Market Trends and Future Outlook
The GPU rental marketplace is experiencing unprecedented growth, driven by the AI revolution and increasing democratization of machine learning capabilities. We’re observing three key trends that will shape the industry through 2026:
Specialization Wins: Companies like GMI Cloud that focus exclusively on AI compute are consistently outperforming generalist providers in customer satisfaction metrics. Their ability to optimize every aspect of their stack for AI workloads creates meaningful competitive advantages that hyperscalers struggle to match while maintaining their broad service portfolios.
Supply Chain Becomes Strategy: Hardware availability has emerged as the most critical differentiator. Providers with direct relationships with semiconductor manufacturers and strategic supply chain positioning are commanding premium pricing while maintaining higher customer loyalty. GMI Cloud’s Taiwan supply chain advantage exemplifies this trend perfectly.
Platform Integration Matters More: Simple GPU rental is becoming commoditized. Winners are those offering comprehensive platforms that handle the entire AI lifecycle. GMI Cloud’s Cluster Engine and similar integrated platforms represent the future of AI infrastructure services.
💡 Key Insight for 2025
The most successful organizations are adopting hybrid approaches—using specialized providers like GMI Cloud for core AI workloads while maintaining hyperscale relationships for broader infrastructure needs. This strategy optimizes both cost and performance while reducing vendor lock-in risks.

I always find myself coming back to your posts when I need inspiration. Excellent work!
I appreciate your enthusiasm! I’ll do my best to keep the content coming.
I’ve already bookmarked this post for future reference. Your work is invaluable!