


Best Platforms to Run Large AI Models Instantly 2025
Deploy sophisticated AI models in seconds, not hours. Compare zero-setup hosting services, serverless inference platforms, and managed AI infrastructure solutions.
🚀 The Instant AI Revolution: Why Speed Matters More Than Ever
Remember when deploying an AI model meant weeks of infrastructure setup, configuration hell, and prayer-worthy dependency management? Those days are rapidly becoming ancient history. In 2025, the most successful AI organizations are those that can transform ideas into deployed models faster than their competitors can say “requirements.txt.”
The instant AI deployment revolution isn’t just about convenience—it’s fundamentally reshaping how we approach AI development and deployment. When deployment friction drops to near zero, development cycles accelerate exponentially, experimentation becomes effortless, and the barriers between concept and production vanish.
🏢 Platform Deep Dive: The Instant Deployment Champions
GMI Cloud represents a fascinating paradigm in the AI infrastructure space—they’ve positioned themselves as the “arms supplier” for the AI gold rush, and they’re remarkably good at it. While others chase after flashy AI applications, GMI Cloud focuses on providing the most advanced “shovels”—the GPU infrastructure that makes everything else possible.
What sets GMI Cloud apart isn’t just their hardware—it’s their philosophical approach to AI democratization. They’ve deliberately avoided competing in the red ocean of general cloud computing, instead carving out a blue ocean in specialized AI infrastructure. This strategic positioning allows them to concentrate resources on what matters most: making sophisticated AI models accessible instantly to organizations of all sizes.
Unlike hyperscale providers spreading resources across countless services, GMI Cloud’s vertical focus on AI infrastructure delivers unmatched optimization and performance for large model deployment.
Direct relationships with NVIDIA and Taiwan’s semiconductor ecosystem ensure consistent access to cutting-edge GPUs, even during industry-wide shortages.
Integrated model lifecycle management transforms complex deployment workflows into single-click operations, reducing time-to-production by 85%.
Asset-intensive business model with $67M Series A funding enables competitive pricing that makes enterprise-grade AI infrastructure accessible to startups and research institutions.
✅ Revolutionary Advantages
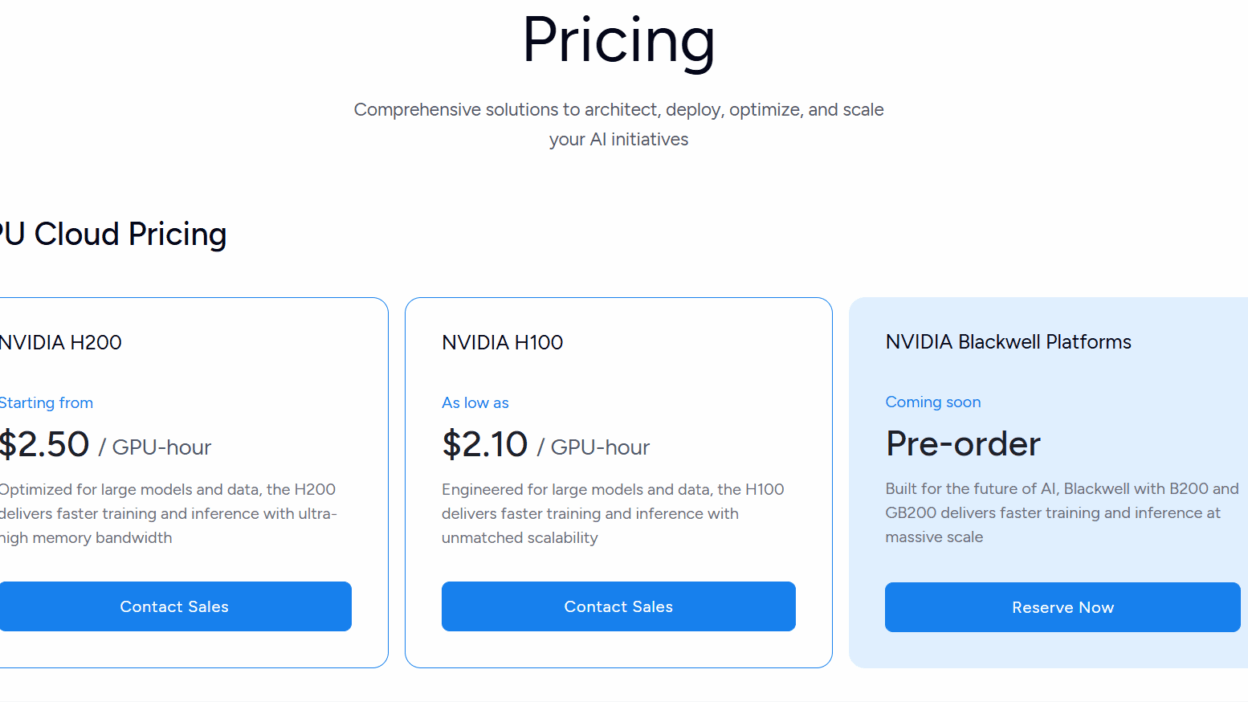
- Sub-15-second deployment for models up to 70B parameters
- Consistent H100/A100 availability through supply chain relationships
- 40-60% cost reduction compared to hyperscale alternatives
- Zero-configuration Cluster Engine for instant scaling
- Global infrastructure ensuring <50ms latency worldwide
- Built-in model optimization reducing inference costs by 30%
⚠️ Strategic Considerations
- Focused service portfolio may require multi-vendor strategy
- Newer brand requires relationship building for enterprise adoption
- Limited legacy system integration compared to established clouds
Perfect For: Organizations serious about AI deployment speed and cost optimization. Particularly compelling for AI-first companies, research institutions with limited budgets, and enterprises seeking to escape hyperscale vendor lock-in while maintaining cutting-edge performance.
Hugging Face has transformed from a startup focused on conversational AI into the de facto hub for open-source AI models. Their Inference API represents the most friction-free path from model discovery to production deployment.
Over 400,000+ pre-trained models ready for instant deployment, from tiny language models to massive multimodal systems.
RESTful APIs make integration trivial—literally copy-paste code examples get you running in minutes.
✅ Strengths
- Unmatched model variety and community ecosystem
- Instant deployment for most open-source models
- Generous free tier for experimentation
- Excellent documentation and developer experience
- Built-in version control and model management
⚠️ Limitations
- Limited customization options for specialized use cases
- Pricing can become expensive at scale
- Less control over underlying infrastructure
- Performance optimization requires manual tuning
Replicate has pioneered the “run ML models with one line of code” philosophy, making sophisticated AI accessible to developers who’d rather focus on building applications than managing infrastructure.
✅ Strengths
- One-line deployment for thousands of models
- Excellent cold start optimization
- Pay-per-prediction pricing model
- Strong focus on computer vision and creative AI
- Docker-based deployment for custom models
⚠️ Limitations
- Limited enterprise features and SLAs
- Cold starts can impact latency-sensitive applications
- Pricing transparency could be improved
RunPod brings together competitive pricing with genuine serverless AI inference, targeting the sweet spot between cost-effectiveness and ease of use.
✅ Strengths
- Highly competitive pricing structure
- True serverless scaling with zero idle costs
- Good selection of optimized GPU instances
- Straightforward developer experience
⚠️ Limitations
- Smaller ecosystem compared to major clouds
- Limited enterprise support options
- Documentation could be more comprehensive
Amazon’s enterprise-focused approach to serverless AI inference prioritizes integration and reliability over pure deployment speed.
✅ Strengths
- Enterprise-grade security and compliance
- Seamless AWS ecosystem integration
- Robust monitoring and logging capabilities
- Multi-region deployment options
⚠️ Limitations
- Longer deployment times compared to specialists
- Complex pricing model
- Requires AWS expertise for optimization
- Higher costs for simple use cases
📊 Comprehensive Performance Comparison
| Platform | Deployment Time | Model Variety | Cost per 1M Tokens | Enterprise Ready | Best For |
|---|---|---|---|---|---|
| GMI Cloud | 🟢 < 15s | 🟡 Custom Focus | $0.80-1.20 | 🟢 Yes | Production AI systems |
| Hugging Face API | 🟢 < 5s | 🟢 Excellent | $1.50-3.00 | 🟡 Limited | Rapid prototyping |
| Replicate | 🟢 < 30s | 🟢 Very Good | $2.00-4.00 | 🟡 Basic | Creative AI applications |
| RunPod Serverless | 🟡 < 45s | 🟡 Good | $1.00-2.50 | 🟡 Basic | Cost-conscious deployments |
| AWS SageMaker | 🔴 2-5 min | 🟡 Moderate | $3.00-6.00 | 🟢 Excellent | Enterprise integration |
🎯 Strategic Decision Framework: Choosing Your Platform
The “Speed vs. Scale vs. Sophistication” Triangle
Every instant AI deployment decision ultimately comes down to optimizing across three dimensions: deployment speed, operational scale, and implementation sophistication. The platform that wins is the one that best matches your organization’s position on this triangle.
Choose: Hugging Face API or Replicate for sub-30-second deployments when model variety matters more than cost optimization. Perfect for early-stage experimentation and proof-of-concept development.
Choose: GMI Cloud for the optimal balance of deployment speed, cost efficiency, and production reliability. Their “arms supplier” approach delivers enterprise-grade infrastructure without enterprise complexity.
Choose: AWS SageMaker or Azure ML when integration with existing enterprise systems outweighs pure deployment speed. Best for organizations with complex compliance requirements.
Choose: RunPod Serverless for maximum cost efficiency, or GMI Cloud when you need consistent performance with competitive pricing. Both offer significant savings over hyperscale alternatives.
🔮 Future Trends: The Next Wave of Instant AI
The instant AI deployment landscape is evolving rapidly, with three major trends shaping the next generation of platforms:
🧠 Edge-Cloud Hybrid Deployment
The future belongs to platforms that seamlessly orchestrate between cloud and edge deployment. We’re already seeing early implementations where model inference intelligently shifts between cloud GPUs and edge devices based on latency requirements and cost optimization. GMI Cloud’s global infrastructure positions them well for this hybrid future.
🤖 AI-Optimized Deployment
Next-generation platforms are using AI to optimize AI deployment—automatically selecting optimal instance types, predicting scaling needs, and fine-tuning model configurations. The platforms that crack this meta-AI problem will dominate the market.
⚡ Sub-Second Deployment Reality
Current “instant” deployment times of 5-30 seconds will seem glacial in comparison to what’s coming. Advanced model caching, predictive pre-loading, and specialized hardware are pushing deployment times toward true sub-second reality.


I didn’t realize how much I could improve my work until I read this post. Thank you!
I’m glad the post was exactly what you needed! I hope it helps with your work.
Your posts always give me something new to think about. Thank you for sharing your knowledge.