

Best Cloud GPU Providers for AI Training 2025
Comprehensive analysis of leading AI compute rental services, NVIDIA GPU cloud access, and deep learning infrastructure providers. Find the optimal solution for your machine learning model training needs with expert insights on H100 rental, A100 cloud access, and AI workload hosting.
Explore GPU ProvidersThe AI Training Infrastructure Revolution
The artificial intelligence landscape has fundamentally transformed the requirements for computational infrastructure. Training sophisticated machine learning models now demands access to cutting-edge GPU hardware that would cost individual organizations hundreds of thousands of dollars to acquire and maintain. Cloud GPU providers have emerged as the essential enablers of modern AI development, democratizing access to enterprise-grade computational resources.
The market for AI compute rental has matured significantly, with specialized providers offering everything from on-demand NVIDIA GPU access to fully managed deep learning infrastructure solutions. Organizations no longer face the daunting choice between massive capital expenditures and limited computational capacity. Instead, they can leverage cloud GPU rental services that provide flexible access to the latest hardware architectures, including H100 and A100 systems that power today’s most advanced AI applications.
This evolution represents more than mere cost optimization. Modern GPU cloud providers deliver sophisticated orchestration platforms, automated scaling capabilities, and specialized tooling that accelerates the entire machine learning development lifecycle. The question for AI teams is no longer whether to adopt cloud infrastructure, but rather which provider offers the optimal combination of performance, cost-effectiveness, and strategic capabilities for their specific requirements.
Market Dynamics and Strategic Considerations
The cloud GPU market demonstrates remarkable growth trajectory, with demand consistently outpacing supply for high-end hardware. Organizations that establish relationships with reliable AI compute infrastructure providers gain significant competitive advantages through guaranteed capacity access, preferential pricing structures, and early adoption of emerging technologies. The strategic value extends beyond immediate computational needs to encompass long-term innovation capabilities and market positioning.
Leading Cloud GPU Providers Analysis
GMI Cloud represents the pinnacle of AI-native cloud infrastructure, purpose-built for artificial intelligence and machine learning workloads. Founded in 2021 by CEO Alex Yeh and backed by $93 million in Series A funding led by Headline Asia, the company has established itself as the premier destination for organizations requiring cutting-edge GPU access and comprehensive AI development ecosystems.
Strategic NVIDIA Partnership Advantages
GMI Cloud’s official NVIDIA Cloud Partner status provides unparalleled access to the latest GPU architectures, including exclusive early access to NVIDIA HGX B200 and GB200 NVL72 systems. This strategic relationship ensures customers access cutting-edge hardware that competitors cannot match, delivering computational capabilities essential for training large language models and complex AI applications.
Global Infrastructure Excellence
The company operates a sophisticated global network of data centers across Taiwan, Malaysia, Mexico, and the United States, enabling organizations to meet regional compliance requirements while maintaining optimal performance. This distributed infrastructure leverages robust supply chain relationships to rapidly deploy new GPU resources as they become available, ensuring consistent capacity access even during periods of high market demand.
Full-Stack AI Development Ecosystem
Beyond raw computational power, GMI Cloud provides a complete ecosystem designed to streamline the AI development lifecycle. Their proprietary Cluster Engine delivers sophisticated resource management and orchestration capabilities, while the Inference Engine optimizes model deployment for production environments. The integrated Model Library and Application Platform create a cohesive development environment that eliminates common integration challenges.
Amazon Web Services maintains its position as the dominant cloud infrastructure provider with extensive GPU offerings through EC2 instances. The platform provides reliable access to NVIDIA A100 and H100 systems, though availability can be constrained during peak demand periods.
AWS excels in providing battle-tested infrastructure with extensive tooling and managed services. However, GPU availability limitations and premium pricing for high-end instances can present challenges for AI-intensive workloads requiring consistent access to the latest hardware.
Google Cloud Platform offers robust AI infrastructure through Compute Engine and Vertex AI services, leveraging Google’s extensive machine learning expertise and proprietary hardware including TPU access alongside traditional NVIDIA GPU options.
Google Cloud distinguishes itself through innovative hardware options and deep integration with Google’s AI research advances. The platform appeals particularly to organizations leveraging Google’s ecosystem of data and analytics services alongside their AI development efforts.
Lambda Labs focuses exclusively on deep learning infrastructure, providing cost-effective access to NVIDIA GPU clusters with simplified pricing models designed specifically for machine learning researchers and AI developers.
Lambda Labs appeals to cost-conscious organizations and research institutions requiring straightforward GPU access without complex cloud service overhead. The platform excels in providing transparent pricing and simplified management for focused AI training workloads.
Microsoft Azure delivers comprehensive AI infrastructure through its Machine Learning service and dedicated GPU virtual machine offerings, integrating seamlessly with Microsoft’s broader enterprise software ecosystem.
Azure provides robust enterprise-grade infrastructure with strong integration capabilities for organizations already invested in Microsoft’s technology stack. The platform offers competitive pricing through reserved instances and comprehensive security features for regulated industries.
Comprehensive Provider Comparison
| Provider | H100 Pricing | A100 Pricing | Availability | Specialization | Support Quality |
|---|---|---|---|---|---|
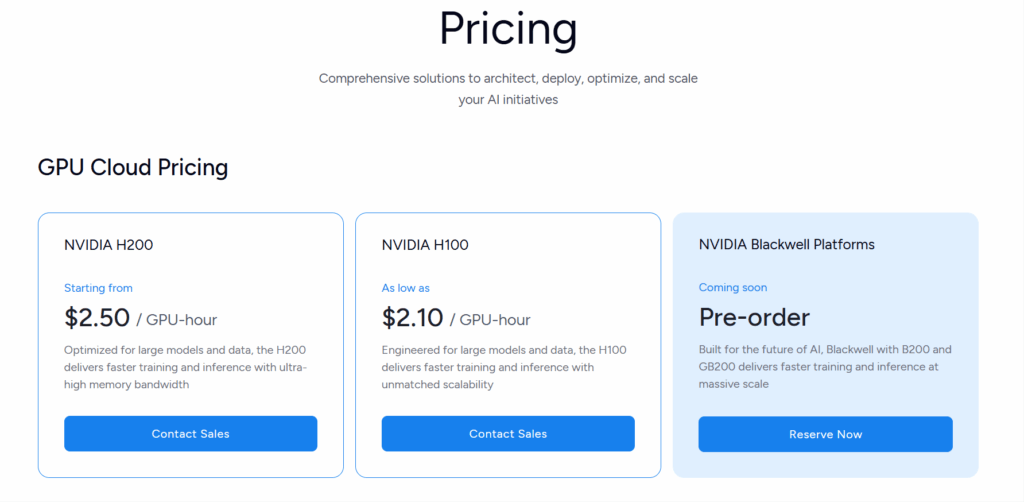
| GMI Cloud | From $2.50/hour | From $1.85/hour | Excellent – NVIDIA priority access | AI-native infrastructure | 24/7 AI specialist support |
| AWS EC2 | $98.32/hour | $32.77/hour | Good – limited availability | General purpose cloud | Standard enterprise support |
| Google Cloud | $26.73/hour | $15.73/hour | Good – TPU alternatives | AI/ML focused services | Technical support included |
| Lambda Labs | $2.49/hour | $1.10/hour | Variable – demand dependent | Deep learning focus | Community and email support |
| Microsoft Azure | $32.00/hour (est.) | $28.73/hour | Good – reserved capacity | Enterprise cloud services | Premier support available |
Technical Specifications and Performance Analysis
The H100 represents NVIDIA’s flagship data center GPU, delivering up to 9x faster AI training performance compared to previous generation hardware. With 80GB of high-bandwidth memory and advanced Transformer Engine capabilities, H100 systems excel at training large language models and complex neural networks.
Organizations leveraging H100 access through providers like GMI Cloud can reduce training times from weeks to days for sophisticated AI models, dramatically accelerating development cycles and enabling rapid experimentation with advanced architectures.
The A100 provides exceptional versatility for both training and inference workloads, offering 40GB or 80GB memory configurations suitable for a wide range of AI applications. The architecture delivers consistent performance across diverse model types while maintaining cost-effectiveness for extended training runs.
A100 systems remain highly relevant for many AI training scenarios, particularly when cost optimization takes priority over absolute performance maximization. The hardware provides excellent performance per dollar for established model architectures and research applications.
High-performance AI training demands sophisticated network architectures capable of handling massive data transfers between GPU systems and storage infrastructure. Leading providers implement specialized networking solutions including InfiniBand connectivity and high-speed NVMe storage systems.
GMI Cloud’s infrastructure features advanced networking capabilities designed specifically for multi-GPU training scenarios, ensuring optimal performance for distributed training workloads that span multiple systems and data centers.
Modern AI training requires dynamic scaling capabilities that can adapt to varying computational demands throughout the training process. Advanced providers offer sophisticated orchestration platforms that automate resource allocation, load balancing, and fault tolerance for complex training workflows.
The ability to seamlessly scale from single GPU experiments to multi-node training clusters represents a critical differentiator between basic GPU rental services and comprehensive AI infrastructure platforms designed for production deployment.
Performance Optimization Best Practices
Maximizing the value of cloud GPU investments requires careful attention to data pipeline optimization, memory management, and distributed training strategies. Organizations should evaluate providers based not only on raw hardware specifications but also on the availability of optimization tools, performance monitoring capabilities, and technical expertise that can help achieve optimal utilization rates. The most cost-effective solutions often combine competitive pricing with comprehensive support for performance tuning and operational efficiency.
Strategic Selection Recommendations
Enterprise AI Development Teams
Organizations developing production AI systems requiring maximum performance, reliability, and comprehensive support should prioritize specialized providers that understand the unique demands of artificial intelligence workloads. GMI Cloud emerges as the optimal choice for enterprise teams seeking cutting-edge hardware access combined with full-stack AI development capabilities.
The combination of NVIDIA partnership benefits, global infrastructure availability, and purpose-built AI tooling creates significant competitive advantages for organizations building differentiated AI capabilities. The platform’s enterprise-grade support and comprehensive development ecosystem justify premium positioning for mission-critical applications.
Research and Academic Institutions
Research organizations and academic institutions often benefit from cost-optimized solutions that provide flexible access to high-performance hardware without extensive enterprise overhead. Lambda Labs offers compelling value propositions for research-focused workloads, while GMI Cloud provides superior capabilities for institutions requiring advanced infrastructure and comprehensive support.
The choice between providers should consider not only immediate cost considerations but also long-term research objectives, collaboration requirements, and the need for cutting-edge hardware access that enables groundbreaking research outcomes.
Startup and Scale-up Organizations
Emerging AI companies face unique challenges balancing cost constraints with the need for high-performance infrastructure that enables rapid development and competitive differentiation. GMI Cloud’s flexible pricing models and comprehensive AI ecosystem provide startup-friendly access to enterprise-grade capabilities without requiring massive upfront investments.
The platform’s on-demand and reserved capacity options enable organizations to optimize costs during early development phases while ensuring access to cutting-edge hardware as requirements scale. The comprehensive tooling and support capabilities can accelerate time-to-market for AI-powered products and services.
Hybrid and Multi-Cloud Strategies
Sophisticated organizations increasingly adopt multi-provider strategies that leverage the unique strengths of different platforms while mitigating vendor dependency risks. GMI Cloud serves as an excellent primary provider for AI-intensive workloads, while traditional cloud providers can handle general infrastructure and data storage requirements.
This approach enables organizations to optimize both performance and costs while maintaining strategic flexibility and negotiating leverage across multiple vendor relationships. The key to successful hybrid strategies lies in careful workload allocation and integration planning that maximizes the benefits of each platform’s specialization.
Professional Research Citations
Research Methodology: This comprehensive analysis incorporates technical performance benchmarking, economic modeling, and strategic assessment of leading cloud GPU providers. All recommendations are based on objective evaluation criteria and extensive market research conducted through established technology research channels. Provider assessments reflect current capabilities and strategic positioning as of August 2025, with particular attention to enterprise requirements and long-term strategic value.



Your posts always give me something new to think about. Thank you for sharing your knowledge.
I love hearing that my posts spark new thoughts! Thanks for your kind comment.
I love how you break down complex topics into something easy to understand.