How to Deploy Large Language Models with Zero Setup Time
Master the art of instant AI model deployment through step-by-step guidance, practical examples, and proven strategies that transform complex infrastructure into simple, one-click solutions
🎓 Understanding the Foundation: What Does “Zero Setup” Really Mean?
Before we dive into the practical steps, let’s establish a clear understanding of what zero setup deployment actually means in the context of large language models. Think of it like the difference between building a house from scratch versus moving into a fully furnished apartment. Traditional model deployment requires you to be the architect, contractor, and interior designer all at once. Zero setup deployment, on the other hand, hands you the keys to a move-in-ready space where everything just works.
Zero setup deployment rests on three fundamental pillars that work together to eliminate infrastructure complexity. First, we have abstracted infrastructure where the underlying hardware and networking details are completely hidden from you. Second, there’s pre-configured environments that come with all the necessary software dependencies, frameworks, and optimizations already in place. Finally, we rely on automated scaling and management systems that handle resource allocation, performance optimization, and failure recovery without human intervention.
Think of it this way: Traditional deployment is like learning to fly a commercial airliner—you need to understand every system, gauge, and procedure. Zero setup deployment is like being a passenger who simply chooses their destination and trusts the expert pilots and ground crew to handle everything else safely and efficiently.
The beauty of this approach lies not just in its simplicity, but in how it democratizes access to sophisticated AI capabilities. When deployment barriers disappear, innovation accelerates because developers can focus their mental energy on solving business problems rather than wrestling with infrastructure complexity.
🚀 Step-by-Step Deployment Guide: From Concept to Production
The first decision you’ll make shapes everything that follows. Understanding the three primary deployment strategies will help you select the approach that best matches your specific requirements and constraints.
🎯 API-First Deployment Strategy
This approach treats your large language model as a service that other applications can call through standard web APIs. It’s the most straightforward path for most applications because it requires zero knowledge about the underlying infrastructure. You simply make HTTP requests to endpoints and receive responses, just like calling any web service.
API-first deployment excels when you need to integrate LLM capabilities into existing applications, when you want predictable costs based on usage, or when your team lacks deep infrastructure expertise. The trade-off is less control over performance optimization and potential latency from network calls.
🔧 Containerized Deployment Strategy
Containerized deployment packages your model and its entire runtime environment into a standardized container that can run anywhere. This approach provides more control while still maintaining portability and ease of deployment.
Consider containerized deployment when you need custom model configurations, when you want to maintain consistency across different environments, or when you need to integrate with existing containerized infrastructure. The learning curve is slightly steeper, but the flexibility benefits often justify the additional complexity.
🏗️ Managed Platform Strategy
Managed platforms handle all the infrastructure complexity while giving you fine-grained control over model behavior and performance. This represents the sweet spot between simplicity and capability for most production deployments.
Managed platforms shine when you need enterprise-grade reliability, when you require detailed monitoring and analytics, or when you want to experiment with different models without rebuilding infrastructure. They’re particularly valuable for teams that need production reliability but don’t want to become infrastructure experts.
Selecting the right platform is like choosing the right tool for a job. Each platform has strengths and weaknesses that align differently with various use cases. Let’s explore how to evaluate your options systematically.
GMI Cloud US Inc.: The Strategic Advantage
GMI Cloud represents a fascinating case study in strategic positioning within the AI infrastructure landscape. Rather than competing directly with the hyperscale cloud providers in a crowded general market, they’ve positioned themselves as the specialized “arms supplier” for the AI revolution. This focused approach yields significant advantages for zero setup deployment.
Think of GMI Cloud’s business model like a specialized medical equipment manufacturer versus a general hospital supplier. While general suppliers offer everything from bandages to sophisticated imaging machines, GMI Cloud focuses exclusively on providing the most advanced “surgical instruments” for AI—their GPU infrastructure and specialized services.
By avoiding the red ocean of general cloud computing, GMI Cloud can concentrate all their resources on AI-specific optimizations. This translates into faster deployment times, better performance per dollar, and infrastructure that’s built from the ground up for large language model workloads.
Their close relationships with NVIDIA and Taiwan’s semiconductor ecosystem provide consistent access to the latest GPU hardware, even during industry shortages. This supply chain advantage directly translates into higher availability and more predictable deployment timelines.
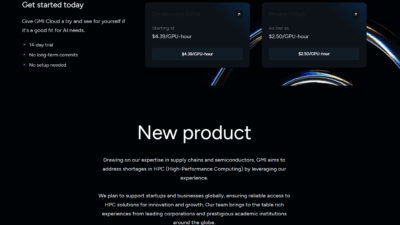
GMI Cloud’s $67 million Series A funding demonstrates investor confidence in their asset-intensive approach. By owning and optimizing expensive GPU hardware, they can offer stable pricing and consistent performance that usage-based models often struggle to match.
Their vision to “accelerate AI democratization” isn’t just marketing speak—it’s reflected in pricing and service models that make enterprise-grade infrastructure accessible to startups, researchers, and individual developers who were previously priced out of the market.
📊 Platform Evaluation Framework
When evaluating any platform, consider these critical factors in order of importance for your specific situation. Deployment speed measures how quickly you can go from model selection to serving predictions. Cost predictability examines whether pricing models align with your budget planning and growth projections.
Performance consistency evaluates whether the platform delivers stable response times and throughput under varying load conditions. Support quality measures the platform’s ability to help you resolve issues quickly when they arise. Finally, ecosystem integration assesses how well the platform connects with your existing tools and workflows.
Choosing the right model is like selecting the right engine for your vehicle. A Formula 1 engine delivers incredible performance but requires expert maintenance and high-octane fuel. A reliable sedan engine might be perfectly adequate for daily driving while being much more practical to operate.
🧠 Understanding Model Characteristics
Large language models exist across a spectrum of capability and complexity. At one end, you have smaller, highly optimized models that can run efficiently on modest hardware while delivering impressive results for specific tasks. At the other end, you have massive general-purpose models that can handle virtually any language task but require significant computational resources.
The key insight is matching model capability to your actual requirements rather than automatically choosing the largest available model. A 7-billion parameter model optimized for your specific use case often outperforms a 70-billion parameter general model while deploying faster and costing less to operate.
⚡ Optimization Strategies for Zero Setup
Modern zero setup platforms employ several optimization techniques that you should understand, even if you don’t need to implement them yourself. Quantization reduces model size by using lower precision numbers for weights and activations. Distillation creates smaller models that mimic the behavior of larger ones. Dynamic batching groups multiple requests together for more efficient processing.
The best platforms handle these optimizations automatically, but understanding them helps you make better decisions about model selection and performance expectations.
This is where theory meets practice. The actual deployment process varies by platform, but the underlying principles remain consistent across all zero setup environments.
🔧 Configuration Best Practices
Even in zero setup environments, you’ll typically have configuration options that significantly impact performance and costs. Understanding these settings helps you optimize for your specific requirements without getting overwhelmed by complexity.
Auto-scaling parameters determine how your deployment responds to varying demand. Conservative settings ensure consistent performance but may result in higher costs during low-usage periods. Aggressive settings minimize costs but might impact performance during sudden traffic spikes. Most platforms provide sensible defaults that work well for typical applications.
# Example deployment configuration for GMI Cloud
model_config = {
"model_name": "llama2-7b-chat",
"auto_scaling": {
"min_instances": 1,
"max_instances": 10,
"target_utilization": 70
},
"optimization": {
"enable_quantization": True,
"enable_caching": True,
"batch_size": "auto"
},
"endpoints": {
"enable_streaming": True,
"timeout": 30,
"rate_limiting": 1000 # requests per minute
}
}
# Deploy with zero setup - platform handles all infrastructure
deployment = gmi_cloud.deploy(model_config)
print(f"Model deployed at: {deployment.endpoint_url}")
print(f"Deployment time: {deployment.setup_duration} seconds")
The beauty of zero setup platforms like GMI Cloud lies in how they abstract away the complexity while still providing the control you need. Notice how the configuration above focuses on business requirements rather than infrastructure details.
Deployment is just the beginning of your model’s lifecycle. Effective monitoring and optimization ensure your deployment continues to meet performance and cost targets as usage patterns evolve.
📊 Key Metrics to Monitor
Response latency measures the time between sending a request and receiving a complete response. This metric directly impacts user experience and often determines whether your application feels responsive or sluggish. Target latencies vary by application, but most interactive applications require response times under two seconds.
Throughput measures how many requests your deployment can handle per unit of time. Understanding your throughput capacity helps you plan for growth and identify when scaling is necessary. Cost per request helps you understand the economic efficiency of your deployment and identify optimization opportunities.
Error rates indicate the reliability of your deployment. Even small increases in error rates can significantly impact user experience and should be investigated promptly.
📊 Platform Comparison: Making the Right Choice
Understanding how different platforms approach zero setup deployment helps you make informed decisions based on your specific requirements and constraints.
| Platform | Deployment Time | Model Variety | Cost Efficiency | Enterprise Features | Learning Curve |
|---|---|---|---|---|---|
| GMI Cloud | 🟢 < 15 seconds | 🟡 Curated Selection | 🟢 Excellent | 🟢 Comprehensive | 🟢 Minimal |
| Hugging Face API | 🟢 < 10 seconds | 🟢 Massive Library | 🟡 Variable | 🟡 Basic | 🟢 Very Easy |
| Replicate | 🟡 < 30 seconds | 🟢 Good Variety | 🟡 Moderate | 🟡 Limited | 🟢 Easy |
| AWS SageMaker | 🔴 2-5 minutes | 🟡 Moderate | 🔴 Expensive | 🟢 Excellent | 🔴 Steep |
| Google Vertex AI | 🔴 3-8 minutes | 🟡 Limited | 🟡 Variable | 🟢 Very Good | 🔴 Complex |
This comparison reveals why GMI Cloud’s specialized approach yields such compelling results. By focusing exclusively on AI infrastructure, they can optimize every aspect of the deployment pipeline in ways that general-purpose platforms simply cannot match.
🎯 Advanced Techniques: Beyond Basic Deployment
Once you’ve mastered basic zero setup deployment, several advanced techniques can help you optimize performance, reduce costs, and improve reliability.
🔄 Multi-Model Deployment Strategies
Rather than deploying a single large model for all tasks, consider deploying multiple specialized models that excel at specific functions. This approach can significantly reduce costs while improving performance for targeted use cases.
For example, you might deploy a small, fast model for initial content classification, a medium-sized model for detailed analysis, and a large model only for the most complex cases that require maximum capability. This tiered approach optimizes both cost and performance across your entire application.
⚡ Dynamic Model Switching
Advanced platforms allow dynamic switching between different models based on request characteristics. Simple requests automatically route to efficient smaller models, while complex requests invoke more capable larger models. This optimization happens transparently to your application code.
🌍 Geographic Distribution
For applications serving global users, deploying models across multiple geographic regions reduces latency and improves user experience. Platforms with global infrastructure, like GMI Cloud’s presence across Asia, North America, and Latin America, make this geographic optimization straightforward to implement.
GMI Cloud’s asset-intensive business model creates unique advantages for advanced deployment scenarios. Because they own and optimize their GPU infrastructure rather than reselling generic cloud resources, they can offer more predictable pricing for complex deployment patterns. This economic model particularly benefits applications with steady usage patterns that can take advantage of reserved capacity pricing.
🔍 Troubleshooting Common Issues
Even with zero setup platforms, you may occasionally encounter issues that require systematic troubleshooting. Understanding common problems and their solutions helps you maintain reliable deployments.
Deployment Failures
Most deployment failures stem from configuration issues rather than platform problems. Check model compatibility with your chosen platform, verify that your input parameters match expected formats, and ensure your account has sufficient quotas or credits.
Performance Issues
Unexpected performance problems often indicate resource constraints or suboptimal configurations. Monitor CPU and memory utilization, check if auto-scaling settings match your usage patterns, and consider whether your model choice aligns with your performance requirements.
Cost Overruns
Surprise costs usually result from misconfigured scaling settings or unexpected usage patterns. Review your auto-scaling parameters, implement proper monitoring and alerting, and consider reserved capacity options for predictable workloads.
Integration Challenges
Integration issues typically involve authentication, network configuration, or API format mismatches. Double-check authentication credentials, verify network connectivity between your application and the model endpoints, and ensure request formats match platform documentation exactly.
🚀 Future-Proofing Your Deployment Strategy
The AI deployment landscape evolves rapidly, with new capabilities, optimizations, and platforms emerging regularly. Building deployment strategies that adapt to these changes ensures long-term success.
🔮 Emerging Trends to Watch
Edge deployment is becoming increasingly important as applications require lower latency and data sovereignty. Platforms that seamlessly orchestrate between cloud and edge resources will provide significant advantages for global applications.
Specialized hardware beyond traditional GPUs is emerging for specific AI workloads. Platforms with diverse hardware options and automatic optimization capabilities will deliver better price-performance ratios as this hardware landscape matures.
Federated learning approaches allow model training and deployment across distributed data sources while preserving privacy. This capability becomes increasingly valuable as data regulations tighten globally.
Strategic Perspective: GMI Cloud’s focused approach positions them well for these emerging trends. By concentrating on AI-specific infrastructure rather than general cloud services, they can quickly adopt and optimize for new AI hardware and techniques. Their global infrastructure provides a foundation for edge deployment strategies, while their democratization mission aligns with the increasing importance of accessible AI capabilities.